


Aztec network, Mojo🔥 release, Google vs OpenAI - CS News #8

Welcome to CS News #8!
CS News helps you keep track of the latest news in different technology domains like AI, Security, Software development, Blockchain/P2P and discover new interesting projects and techniques!
⚙️ Aztec, the hybrid Ethereum zkRollup
Context: Zero knowledge (ZK) proof is a cryptographic method that allows one party to prove to another party that they know a certain piece of information, for example the result of a computation, without revealing the inputs or underlying algorithms used to compute it.
Aztec Labs is a team working on multiple tools related to Zero Knowledge Proof and Ethereum architecture. They raised a $100m series B in December with a simple mission:
At Aztec, our goal is to take the original promise of Ethereum–a decentralized and verifiable world computer–and expand its capability immensely by making it fully encrypted.
One of their project is Noir, a universal language for zero knowledge which any developer can use to create its own ZK circuits with a Rust-like syntax.
Noir’s vision is to be the LLVM for zkSNARKs (a category of Zero Knowledge Proof). Just as programming languages compile to an intermediate representation rather than machine language, Noir compiles to an abstract circuit intermediate representation (ACIR), which can then compile to any cryptographic backend.
They recently announced a new project, which seems to be their main one, called Aztec.
Aztec is our vision for a trustless, scalable, and decentralized Layer 2 zkRollup enabling private smart contract execution.
The goal is to create a rollup, i.e a blockchain network that stores the proof that its state is valid on Ethereum and therefore benefits of Ethereum decentralization and security, that extends Ethereum capabilities.
This rollup includes additional privacy features that use the Aztec execution engine. The engine can verify the state of the rollup blockchain by verifying private transactions without executing them.
This means that users will be able to perform private transactions where the addresses involved in the transaction or the smart contract code executed cannot be seen by others, while maintaining the determinism and verifiability of the blockchain state.
Aztec is still at its early stage and a roadmap for the different test networks has been shared alongside the announcement.

👉 Read more here
🔥 What is Mojo bringing for AI developers
Modular, the company created by Chris Lattner - founder of Swift programming language, LLVM and Clang compiler - aims to propose AI infrastructure tools to support the fast development of this domain. They recently released a new programming language called Mojo 🔥 that “combines the usability of Python with the performance of C, unlocking unparalleled programmability of AI hardware and extensibility of AI models”.
Mojo is a superset of Python, meaning that it is fully compatible with Python code and proposes additional syntax and features, like:
letandvarkeywords for immutable and mutable valuesability to enforce strong type checking alongside a Python-like more dynamic type checking
overloaded functions or methods, to define the same methods with different parameters for example
fnkeyword, used the same way asdefto enforce more strictness on a function like immutable parameters, parameters typing requirement, more explicit exceptions with theraisesfunction effect, placed after the function argument liststructs, which are static classes bound at compile time
An example from the official documentation:
from Pointer import Pointer
from IO import print_no_newline
struct HeapArray:
var data: Pointer[Int]
var size: Int
var cap: Int
fn __init__(self&):
self.cap = 16
self.size = 0
self.data = Pointer[Int].alloc(self.cap)
fn __init__(self&, size: Int, val: Int):
self.cap = size * 2
self.size = size
self.data = Pointer[Int].alloc(self.cap)
for i in range(self.size):
self.data.store(i, val)
fn __del__(owned self):
self.data.free()
fn dump(self):
print_no_newline("[")
for i in range(self.size):
if i > 0:
print_no_newline(", ")
print_no_newline(self.data.load(i))
print("]")
Mojo also provides full compatibility with the Python world, where you can just import a python package with np = Python.import_module("numpy") !
Mojo is made to be compatible with most modern AI infrastructure (gpus, tensors and other AI accelerators) out of the box so that developers can enjoy the best performance while having the simplicity of a language like Python.
👉 Discover Mojo here
Google - "We Have No Moat, And Neither Does OpenAI"
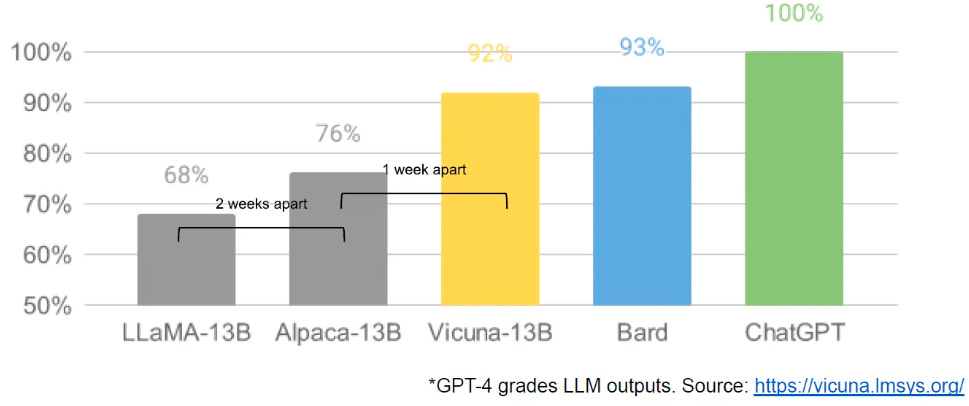
A document originated from a researcher within Google has been leaked stating its opinion on the current state of AI. Keep in mind that it is not an official communication from Google and only a personal opinion from one of its employees.
The document’s author states that as AI is moving faster and faster, we can already manifest some drastic changes in the way of operating:
While not so long ago training a model from scratch was indisputably the way of creating new models, we now see emerging a new era where fine-tuning has become the go-to for creating new models. While training a raw model starts from randomly initialized weights, fine-tuning is a technique used to take a pre-trained model and optimize it for a specific task or domain.
This change, mainly due to the reduction of models’ size, can be sourced to the “releases” of LLaMA by META. LLaMA, offered in several versions with parameter sizes varying from 7B to 65B, was created with the goal of providing access to LLMs to researchers an engineers who lack the necessary data and computation infrastructure to study these models.
LLaMA 7B, rapidly adopted by the community has been the pillar point to fine-tuning LLMs models at low cost. The release of LLaMA-Adapter and alpaca-lora allow individuals to fine-tune LLaMA at a new task in matter of hours without the need of in-deep AI knowledge, mixed with the small size of LLaMA 7B, it allowed anyone with a GPU, a dataset and an idea to fine-tune its own LLM. This exposed two things, first the velocity allowed by small models over larger models, underlining that Google should therefore when possible privilege fine-tuning small models over training from scratch large over-parametrized models as they no longer bring key differentiator values. And secondly, the importance of open AI (not OpenAI) and its impact on Google’s business strategy.
With its striking sentence “We (Google) need them more than they (open source) need us”, the author also explains that google strategy can no longer stay unchanged as Google’s technological advantage keeps being diluted by outside innovations made by the open source community. User now have the choice of either paying to use a closed source mode, or to use a free open source alternative, ****not constrained by licenses to the same degree as corporations. AI companies should thus rethink their business strategy at the risk of losing track against open source solutions.
Instead of “Directly Competing With Open Source” which “Is a Losing Proposition” should rather work with it as META did. Indeed, the leakage of LLaMA and the creation of all those fine-tuned models based on it, has allowed META to “Own[ing] the Ecosystem” thus “garnering an entire planet's worth of free labor”. Google have already applied this strategy for other product like Android and Chrome, “cementing itself as a thought leader and direction-setter” and those respective fields. Google should thus consider “publishing the model weights for small ULM variant“ enabling the community to work on it and create variants of it.
Keep in mind that this document is only a personal opinion of a google employee and not an official statement by the company. It can also be possible that the document has been purposely leaked in order to state it position in this new era of AI.
👉 Read the original blog post